
Can humans and machines co-create generalizable models?
This article contains a description of an AI project which was awarded the “Best Poster Award” by the public at the University of Michigan AI Symposium 2019.
Machine learning techniques, especially deep learning, have been widely applied to solve a variety of problems ranging from classifying email spam to detecting toxic language. However, deep learning often requires a massive amount of labeled training data, which is very costly, and sometimes may be infeasible to obtain. In low-resource settings (e.g. when labeled data is scarce, or when training data only represents a subclass of the testing data), machine learning models tend to not generalize well. For example, reviewing legal contracts is a tedious task for lawyers. To help facilitate the process, machine learning methods can be used to extract documents relevant to certain clauses. However, the company (e.g. IBM) that produces the model can only get a large number of their own contracts, whereas contracts of others (e.g. Google, Apple) is hard to obtain, causing the model trained to overfit and not generalize well on contracts pertinent to other companies.
On the other hand, human experts are able to extrapolate rules from data. Using their domain knowledge, they can create rules that generalize to real world data. For example, while ML models may see a pattern of sentences with past tense are correlated with the clause of communication, and thus use past tense as a core feature for classification, a human would easily recognize that the verbs of the sentences are true reasons why the sentences should be classified this way, thereby creating a rule of “if sentence has verb X, then sentence is related to communication.” However, coming up with rules is very difficult. Human experts often need to manually explore massive size of datasets, which can take up to months.
Our goal is to combine human and machine intelligence to create models that generalize to real world data, even when training data is lacking. The core idea is to first apply an existing deep learning technique to learn first-order-logic rules, and then leverage domain experts to select a trusted set of rules that generalize. By applying the rule learning method this way, the rules serve as an intermediate layer that bridge the explainability gap between humans and the neural network. Such a human-machine collaboration makes use of the machine’s ability to mine potentially interesting patterns from large scale datasets, and the human’s ability to recognize patterns that generalize. We present the learned rules in HEIDL (Human-in-the-loop linguistic Expressions with Deep Learning), an system that facilitates the exploration of rules and integration of domain knowledge.
The learned rules and the features of HEIDL are illustrated below.
What do the rules look like?
Each rule is a conjunction of predicates. Each predicate is a shallow semantic representation of each sentence in the training data, generated by NLP techniques such as semantic role labeling and syntactic parsing. It captures “who is doing what to whom, when, where, and how” described in a sentence. For example, a predicate can be tense is future, or verb X is in dictionary Y. So a rule can simply be tense is future and verb X is in dictionary Y. Each rule can be viewed as a binary classifier. A sentence is classified as true for a label if it satisfies all predicates of the rule.
What are the features of HEIDL?
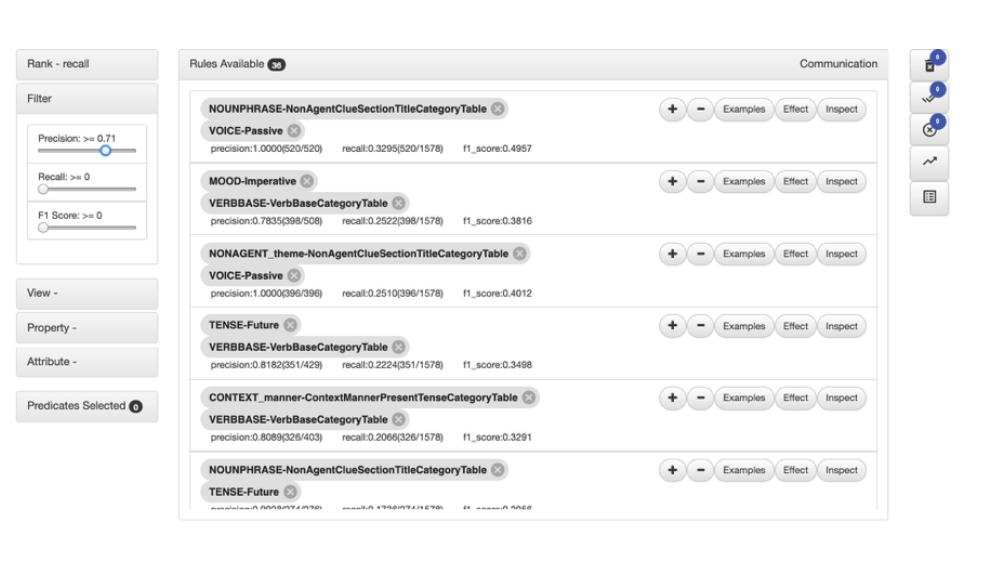
- HEIDL allows expert users to rank, filter rules by precision, recall, f1, and predicates
- After evaluating a rule, users can approve or disapprove it (the final goal is to approve a set of rules that align with the users’ domain knowledge. A sentence is true for a label if it satisfies any rule in the set.)
- The combined performance (precision, recall, F1 score) of all approved rules is updated each time a rule gets approved, helping users to keep track of overall progress
- Users can see the effect on overall performance by hovering over a rule
- Users can modify rules by adding or dropping predicates, and examine the effects
We evaluated the effectiveness of the hybrid approach on the task of classifying legal documents to various clauses (E.g. communication, termination). We recruited 4 NLP engineers as domain experts. The training data is sentences extracted from IBM-procurement contracts, and the testing data is sentences extracted from non IBM-procurement contracts. We compared this approach to a state-of-the-art machine learning model - a bi-directional LSTM trained on top of GloVe embedding, and demonstrated that the co-created rule-based model in HEIDL outperformed the bi-LSTM model.
Our work suggests that the instillation of human knowledge into machine learning models can help improve the overall performance. Further, this work exemplifies how humans and machines can collaborate to augment each other and solve problems that cannot be solved by either alone.
The full paper can be found here: https://arxiv.org/abs/1907.11184
The author of the paper is a student researcher at the University of Michigan. This work was done in collaboration with IBM Research as a summer internship project.